Accidents

GPU小偷:一次诡异的生产事故复盘
March 21, 2026
早晨的诡异异常
3月20日早上,出门跑步回来就发现服务出现了诡异的异常:LLM推理的TTFT从常规的220ms骤降至80ms,足足少了150ms。与此同时,TTS接口开始返回空音频流。

于是我进入了oncall环节。理论上我们的新模型已经上线快两周了,BUG都修复得差不多了,不应该无缘无故出故障。我的第一反应是:机器坏了。
进入Lens查看集群节点状态,K8s显示一切正常——服务是healthy状态,Pod也在正常running。但奇怪的是,服务就是不返回推理内容。
接下来SSH进入推理Pod,调用nvidia-smi查看显卡工作状态,发现部分Pod的nvidia-smi命令无法获取显卡信息。终于,问题定位到了:部分机器出现大规模Pod卡在terminating状态,无法正常退出。
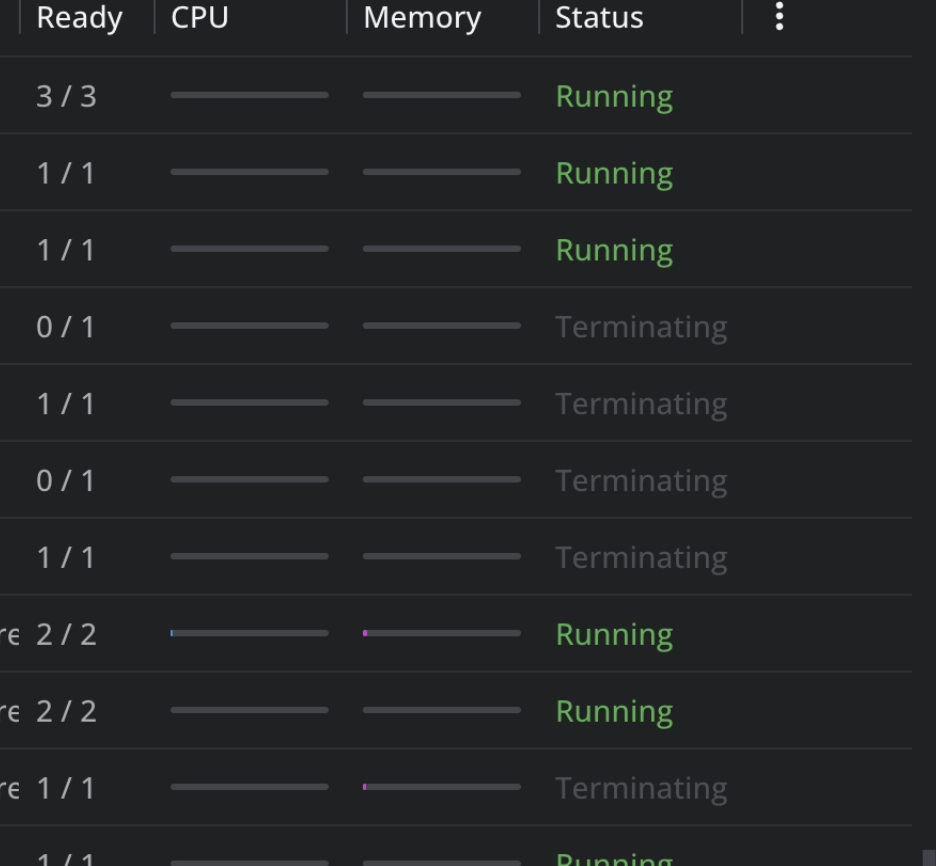
当时还不清楚为什么会卡住。由于Pod内显示CUDA异常,我初步判定为宿主机损坏,快速drain掉故障节点,并强制清理卡顿的Pod,服务随即恢复正常。

诡异的TTFT波动
服务恢复正常后,TTFT仍然波动剧烈。当时并非业务高峰期,进入Pod观察后发现:大部分请求能在150ms内完成首个音频chunk的推理,但有小部分请求需要2000-3000ms。
一时间我以为是推理框架又出现了奇妙BUG,便开始翻看代码查找原因。但由于工期紧任务重,小部分请求的卡顿并不会对绝大多数用户造成致命影响,便暂时搁置这个问题,继续推进正常的迭代开发工作。
梅开二度
时间磕磕绊绊来到了晚上,同样的异常再次出现——又有宿主机节点异常"死去",导致服务小规模故障。这一次我拉上了公司的SRE一起做深度排查。
首先往GPU是否真正损坏的方向排查,发现无果。
接着开始排查其他可能导致CUDA out of memory的服务,这次有了一些苗头——但根因并不是out of memory。
我们发现有位同事写的Pod使用了GPU,却没有在资源申请中声明nvidia.com/gpu: 1。理论上,在没有申请GPU资源的情况下使用GPU,系统会报错"无法找到GPU"。然而,同事的Pod是基于CUDA base image构建的,其Dockerfile中默认设置了NVIDIA_VISIBLE_DEVICES=all。
插播一条背景知识: 在Docker环境中,GPU的声明是通过环境变量
NVIDIA_VISIBLE_DEVICES来管理的。运行echo $NVIDIA_VISIBLE_DEVICES时会得到类似gpu-[uuid]的输出。
回到故事主线。在K8s的Deployment没有声明GPU请求的情况下,CUDA base image的环境变量NVIDIA_VISIBLE_DEVICES=all会默认生效,于是这个Pod就占据了宿主机上全部八张显卡。而在没有开启MPS服务的情况下,各个服务会像CPU分时一样轮流占用GPU。
这就解释了为什么我的TTS推理服务偶尔会出现2000ms的推理延迟——那段时间其实是被其他服务"偷"走了。
故此,我们称之为:GPU小偷。
为什么会把宿主机炸死?
行文至此,我们可以看出:即便没有声明GPU资源,最多也就是当个"小偷",不应该直接把宿主机炸死才对吧?
这时候,真正的主角登场了:KEDA。KEDA是K8s中用于动态扩缩容的服务,这里就不过多展开了。
在推理服务被同事的Pod偷显卡的过程中,推理服务负载过高,触发了KEDA的扩容机制,启动推理服务扩容的同时,系统尝试杀死同事的服务来释放资源。
等等,他明明没申请GPU,为什么要杀这个服务来释放资源?
因为这个Pod里面有三个container,其中一个声明了GPU,另外两个没声明。同事的意图是三个container共享一张显卡。
于是诡异的事情发生了:对显卡有控制权的两个Pod陷入了死锁竞争,导致双方都无法释放资源。
直接原因:NVIDIA驱动内核态rwlock/mutex死锁
内核栈显示两类阻塞:
类型A — 等待rwlock(write): nvidia_close()路径,进程退出时释放GPU资源
do_exit -> __fput -> nvidia_close -> nvidia_close_callback
-> rm_cleanup_file_private -> _nv052958rm -> _nv051484rm
-> os_acquire_rwlock_write [BLOCKED]
类型B — 等待mutex: nvidia ioctl路径,正常GPU操作
nvidia_unlocked_ioctl -> rm_ioctl -> _nv000792rm -> _nv052958rm
-> _nv051492rm -> os_acquire_mutex [BLOCKED]
形成经典的AB-BA死锁:
- 线程A:持有mutex -> 等待rwlock(write)
- 线程B:持有rwlock(read) -> 等待mutex
一旦死锁形成,所有后续nvidia ioctl调用(包括nvidia-smi、新容器创建、CUDA操作)全部被阻塞在D状态(不可中断睡眠),kill -9也无效。
总结
至此,我们完成了对"GPU小偷"事件的完整复盘。
教训很明确:谨慎使用CUDA base image,因为其中可能存在一些我们未知的默认行为。
同时,在使用他人基于这个镜像构建的产物时,也需要多加甄别,避免被"无意"投毒。